Do you want to speed up your Finops practice on Azure?. Here we follow our last post with some simple approaches to allocate cost. Today, we have some nice workarounds and most important very effective to understand our cloud spending. … Continue reading →
Microsoft started his journey to FINOPS as a Premium Founder Member in February 2023. Many IT professionals figured out if this culture and methodologies to leverage cost efficiency would bring value on Azure. After some months the question has a … Continue reading →
SharePoint Online brings a tremendous environment of collaboration to your users. When you are working with partners or employees of your own company located in several subsidiaries in your country, this is the best in class approach.
But what is a file storage service?
A file storage service is a type of online service that allows users to store and access their files over the internet with security and appropriate authorization. Users can upload, download, share, and synchronise their files across different devices and platforms.
Sharepoint Drivers
Drivers to configure and deploy SharePoint are:
Provide easy and convenient access to files from anywhere and anytime.
Enable collaboration and sharing of files with others.
Reduce the need for maintaining physical storage devices and infrastructure.
Offer scalability and flexibility to adjust the storage capacity and performance according to the user’s needs.
Improve user´s mobility and remote work.
So when should i use Sharepoint?
SharePoint is a really powerful solution for collaboration, document process automation, content search, etc.
Sharepoint focus on the following scenarios:
Collaboration solutions with other employees and partners using folders in a structured hierarchy with appropriate permissions.
Intranet to provide current company information such as events, regulations, standardise forms, etc.
Search data such as expertise within the company, projects, people profiles, documents, etc.
Automate processes integrated with IA (together with MS Syntex)
Manage document workflows between departments and document life cycle.
Synchronise collaborative data on your laptop to work at your own pace if needed
Business Intelligent platform
To sum up, SharePoint can offer lots of advantages to your collaboration scenarios.
Enjoy the journey to the cloud with me…see you soon.
As I showed in the previous post Azure file sync needs an agent to be installed in your Windows File Servers thought Windows Admin Center or directly if you download it and install it in your file server. Once it´s done you can proceed to leverage the power of this feature in your global environment, but please take into account the agent is right now only available with the following operating system for your file servers.
Remember to create an Azure file sync, you need an storage account as we did in the previous post, (better general purpose v2), a file share and install the agent on those file server where you want to share data. Then as we did, you can proceed to configure the cloud endpoint and servers endpoint within your sync group on the Azure Portal.
Add the servers from several braches and obviously your head quarter file server..
Verify your servers are synchronized..
Both servers are synchronized
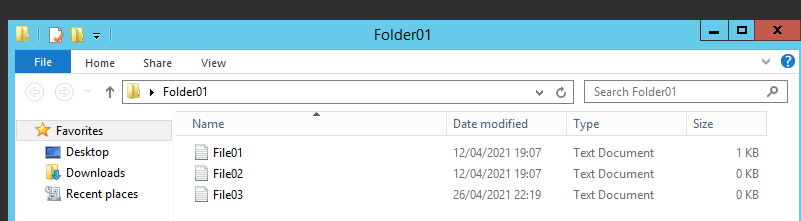
Proceed to create a file in your local head quarter file server..
It is automatically replicated on our example to the branch file server..
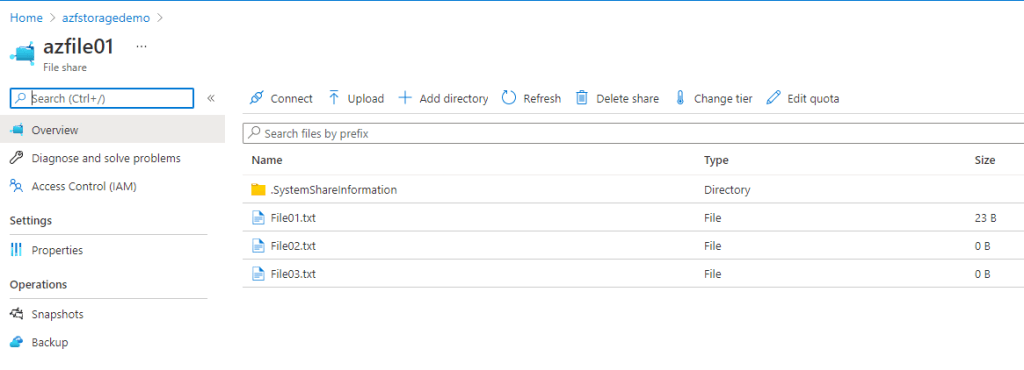
Even if you pay attention to the File share in the Azure Portal you can see all the files from both servers (one in the Head quarter and the other one your branch file server) replicating their data on the File Share in Azure..
Now imagine, you have users all over the world, you need your employees are working on the same page with flexibility and on demand, even you need a backup of that day from time to time and a disaster recovery strategy. Even more, you need to empower your users to be more productive remotely, with their MacOS or Windows Laptops from anywhere.
You can have users working with the same files all around the world and several operating systems (MacOS, Windows 7 , 8.1 or 10 and Linux Ubuntu, Red hat or CentOS) leveraging any protocol that’s available on Windows Server to access your data locally, including SMB, Network File System (NFS), and File Transfer Protocol Service (FTPS). For them it´s transparent where the files are.
But what about performance and scalability?…Well, You can create as much sync groups as your Infrastructure would demand. Just be aware you should design and plan thinking on the amount of data, resiliency and Azure regions where you are extending your business. Anyway it is important to understand the way our data it will be replicated:
Initial cloud change enumeration: When a new sync group is created, initial cloud change enumeration is the first step that will execute. In this process, the system will enumerate all the items in the Azure File Share. During this process, there will be no sync activity i.e. no items will be downloaded from cloud endpoint to server endpoint and no items will be uploaded from server endpoint to cloud endpoint. Sync activity will resume once initial cloud change enumeration completes. The rate of performance is 20 objects per second
Initial sync of data from Windows Server to Azure File share: Many Azure File Sync deployments start with an empty Azure file share because all the data is on the Windows Server. In these cases, the initial cloud change enumeration is fast and the majority of time will be spent syncing changes from the Windows Server into the Azure file share(s).
Set up network limits: While sync uploads data to the Azure file share, there is no downtime on the local file server, and administrators can setup network limits to restrict the amount of bandwidth used for background data upload. Initial sync is typically limited by the initial upload rate of 20 files per second per sync group.
Namespace download throughput When a new server endpoint is added to an existing sync group, the Azure File Sync agent does not download any of the file content from the cloud endpoint. It first syncs the full namespace and then triggers background recall to download the files, either in their entirety or, if cloud tiering is enabled, to the cloud tiering policy set on the server endpoint.
Cloud Tiering enabled. If cloud tiering is enabled, you are likely to observe better performance as only some of the file data is downloaded. Azure File Sync only downloads the data of cached files when they are changed on any of the endpoints. For any tiered or newly created files, the agent does not download the file data, and instead only syncs the namespace to all the server endpoints. The agent also supports partial downloads of tiered files as they are accessed by the user.
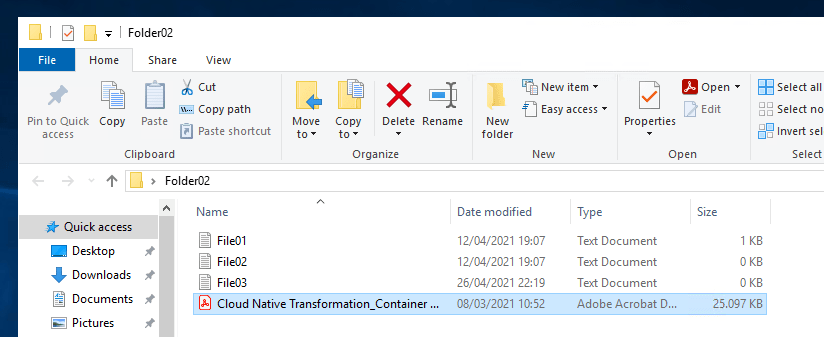
Here I show an example with a 25 MB file. Synchronization was almost immediate as the Sync Groups was already set up. If we upload a file to Folder 02 in our head quarter file server you can see it on the branch in the Folder 01 as well in a matter of second or even less depending on the configuration as we said..
Azure Files supports locally redundant storage (LRS), zone redundant storage (ZRS), geo-redundant storage (GRS), and geo-zone-redundant storage (GZRS). Azure Files premium tier currently only supports LRS and ZRS. That means an incredible potential to replicate data depending on resilience and with solid granularity to several regions in the world.
In the next post we´ll see how to integrate Azure File with AAD or enhance your Windows VDI strategy with FSLogic app containers. See you them..
As i mentioned in a previous post, explaining different alternatives to work in a colaborative way when your company has employees all over the globe https://cloudvisioneers.com/2020/06/06/how-to-consolidate-data-for-small-branches-globally-and-work-together-with-few-investment-i/ , one of the best options in terms of simplicity to share data would be Azure File Sync as you can consolidate data for several file servers. But now as preview you can set up a whole sync folders strategy from Windows Admin Center to consolidate data from branches and head quarters on a file share with all the changes done during the working day.
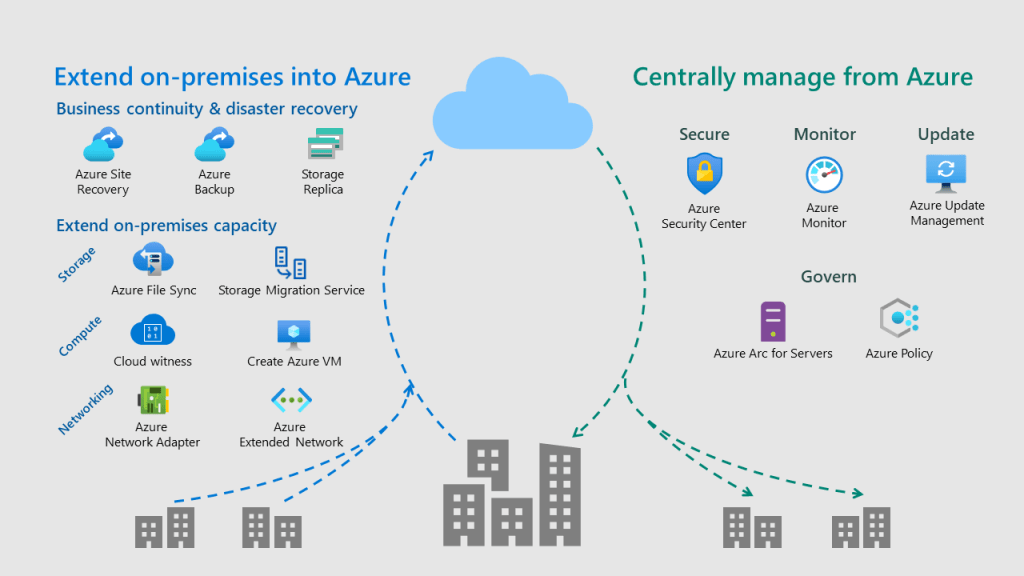
The Azure hybrid services can be manage from Windows Admin Center where you have all your integrated Azure services into a centralized hub.
But what can kind of tasks can we do?
Set up a backup an disaster recovery strategy. – Yes, you can define which data to backup from your file servers on premise to the cloud, retentions as well as determine an strategy to replicate your VMs in Hyper-V using Windows Admin Center.
Planning an storage migration.– Identify and migrate storage from on premise to the cloud based on your previous assessment. Even more not just data from Windows file servers or windows shares but also Linux SMB shares with Samba.
Monitoring events and track logs from on premise servers. – It quite interesting to collect data from on premise in a Log Analytics workspace in Azure Monitor. Then it is very flexible to customize queries to figure out what is happening and when is happening on those servers.
Update and patch your local servers. – With Azure Update Management you have the right solution using Automation that allows you to manage updates and patches for multiple virtual machines on premise or even baremetal.
Consolidate daily work from a distributed data enviroment without limitations on storage or locations. – You can use Windows Admin center to set up as we told before a centralized point for your organization’s file shares in Azure, while keeping the flexibility, performance, and compatibility of an on-premises file servers. In this post, we are going to explain this feature more in depth.
Other features:
Extent your control of your infrastructure with Azure Arc and configure it with Windows Admin Center so, for example, you can run azure policies and configure regulations for your virtual machines a baremetal on prem.
Create VMs on Azure directly from the console.
Manage VMs on Azure from the console.
Even deploy Windows Admin Center in a VM on Azure and work with the console on the cloud.
Now we know some of the important features that you can use with Windows Admin Center, let´s focus on Azure file sync configuration and see how it works.
Let´s start downloading Windows Admin Center from here
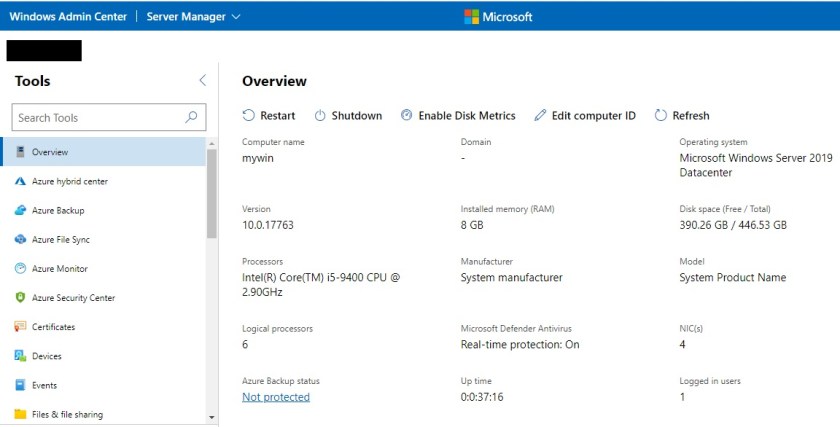
Now after installing you will see the console using the url from local called: https://machinename/servermanager where you can browse information and details of your local or virtual machine and leverage lot of features to manage it.
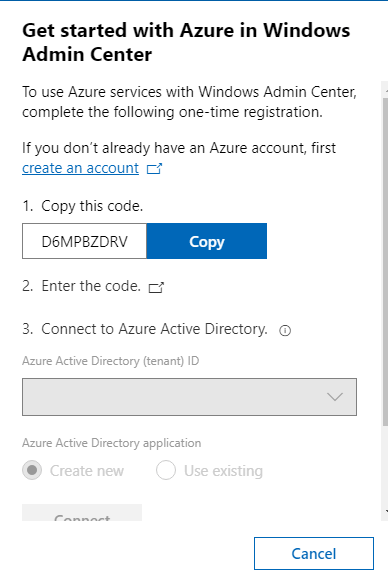
If you click on hybrid center you can configure an account on your azure portal to connect to your azure suscriptions. It will create an Azure AD application from which you can manage gateway user and gateway administrator access if you want in the future. Therefore you will need to first register your Windows Admin Center gateway with Azure. Remember, you only need to do this once for your Windows Admin Center gateway.
You have two options,create a new Azure Active Directory application or use and existing one, on the AAD your choose.
To pointed out here, you can configure MFA for your user later, or create several groups with users for RBAC to work with your Windows Admin Console. Now you will have available several wizards to deploy the strategy it suits better to your business case.
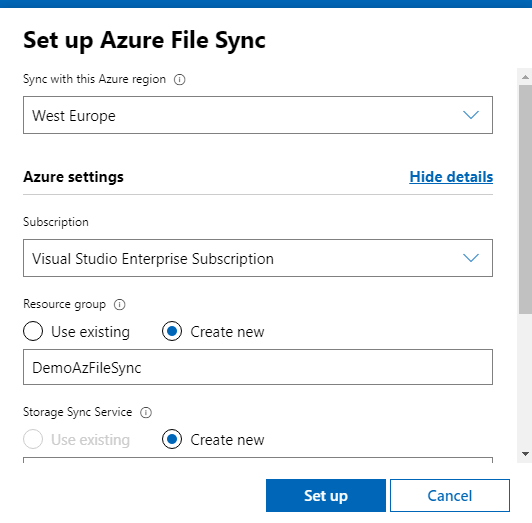
Let´s start configuring all the parameters. Maybe it takes some time to respond, it is on Preview right now (april 2021).
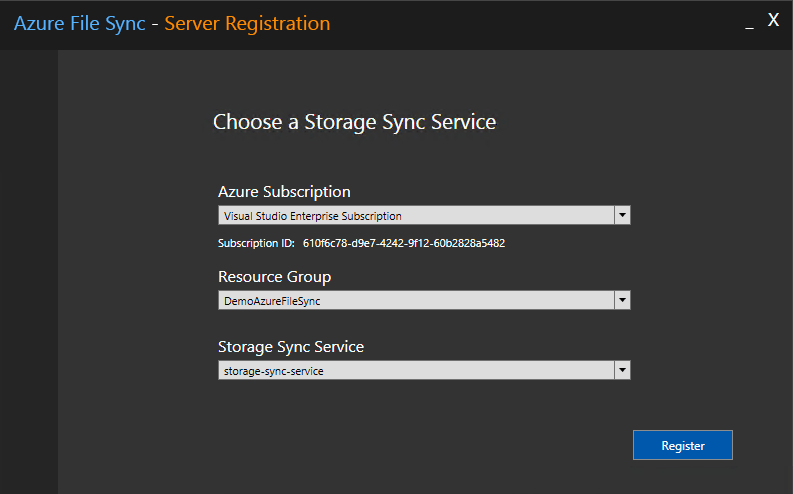
Choose an existing Storage Sync Service or create a new one..
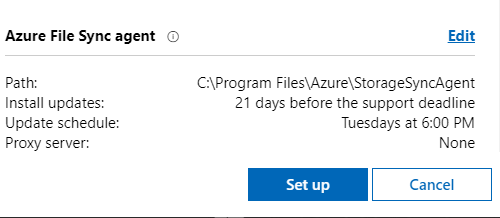
Prepare the Azure File sync agent as needed to be installed on your Windows Admin Center host machine..and hit on “Set up” button.
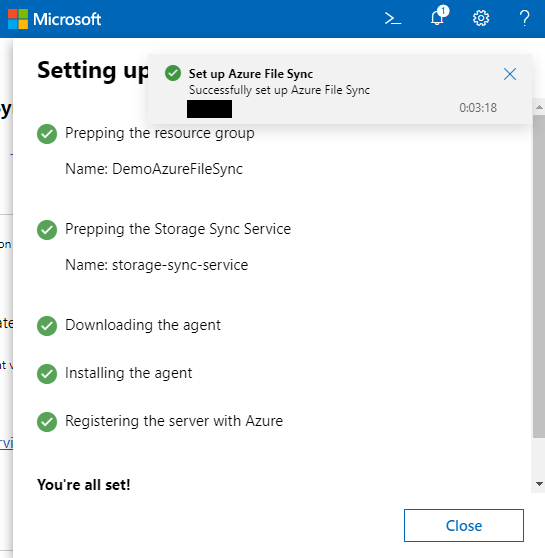
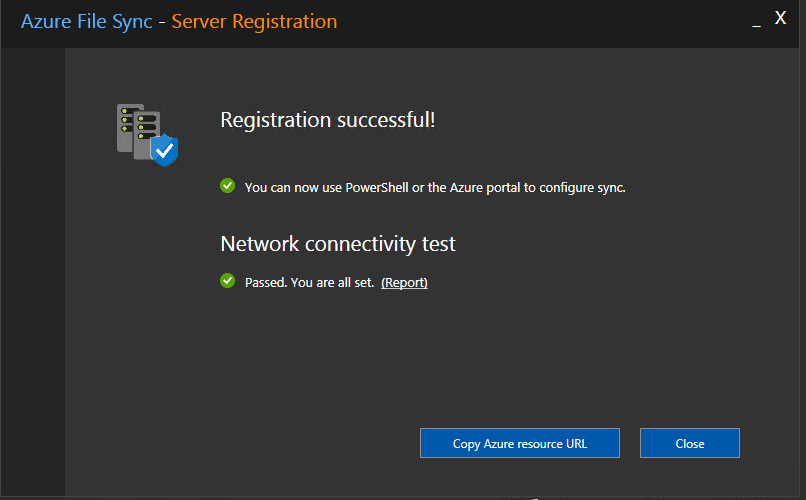
And now register your server on the “Storage sync service”..
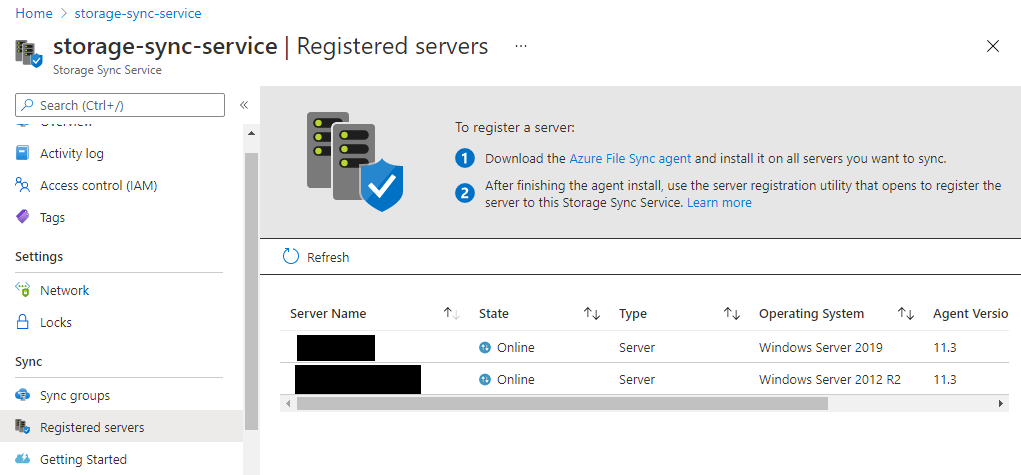
We got to register our new server on Azure File Sync service on Azure to syncronize data on a file share with other File Servers localted all over the world.
Register servers on my Azure suscription
In the next post we´ll configure the following steps to consolidate a global repository using this file share on Azure so all the employees, no matter where they work can be on the same page with the rest of braches and head quarter.
Do you remember some time ago?…but not too many years ago, to consolidate a file share platform for many small branches it was a headache. Not simple, not cheap and with some operational effort not feasible for lots of S&M companies.
You had a file server per branch which should be replicated, using asymmetric replication usually, with others in regular basis. To do that there where several solutions in the market. Some IT departments tried it with Microsoft DFS (Distributed File System) technology, others with Amazon Elastic File System (Amazon EFS) which provides a simple NFS file system for use with the AWS Cloud or on-premises but limited to Linux or Unix world.
Even someone tried it with more budget using Talon CORE and Talon EDGE which works well but means as the other approaches an infrastructure with specific needs to take care of.
No better, no perfect approach but at least a way to share files through many cities, even countries and no IT experts on those locations, with very narrow band communications and poor budget. Do we want to cry?….no, no… 😉
So how to solve the GAP?..here we are:
Use Microsoft Sharepoint Online + One drive– But only if you want to pay Office365 licences and also want to pay a good money for storage as it´s not raw but within a Content Data Base for Office or PDF documents to mention some files (first TERA is included on the SPO Tenant). In the case, you need extra features as Taxonomy search, Fast Search or index content, to put some examples on the table, it a candidate for you. When two employees want to work the same proposal or presentation, they can do it. That´s called coauthoring. Perfect for editing documents at the same time. It is more focus on regions but also Microsoft provide a global solution. If suits your needs and you want it globally you have a new feature called Multi-Geo in SharePoint which enables global businesses control.
Use Microsoft Azure File Sync – If you want the cheapest approach and don´t want to pay for complex maintenance, you don´t need Fast Search or any Content Data base as you are just replicating some files on file on disk storage with any more complex outcome than replicate the changes and facilitate the data for all the employees all over the World. This approach it´s very attractive as brings also the option of using Data Tearing which provides 2 layers for the data in this case, one your “working set”, what you use daily, and the rest of files an folders which will be move to the cloud (depending on policies or volume limits) and only bring back to your local file server if someone needs them. All the local file servers consolidate their data to a file share on the cloud, on Azure, and it is available for employees even with the new changes because any change happens first locally and Azure File Sync will decide which one is the last version on a document to be updated on the cloud file share. On the other hand, you have snapshot if someone did a mistake. You can create as much sync groups as you want with a cloud endpoint, your cloud file share and a Server endpoint or several of them, all the servers that are consolidating folders and files together in the cloud and visible for the employees where ever they are. So perfect solution for concurrence even if you modify the docs locally.
AWS solutions are also a good option. Amazon FSx for Windows File Server resources provides file Systems, backups, and file Shares. It also support DFS as we´ve said before (in the first traditional solutions some years ago) to be integrated with Amazon FSx. If you want also to make it simple you can use S3 (the global storage AWS service) with a private or a public bucket depending on your needs working together with Edge Locations which are facilities present in many countries and accelerate with cache the data access for the users. But keep in mind the collaborative approach in this last case is not so optimal as the Amazon FSx + DFS in terms of concurrence.
Azure also offers Azure Files or NET APP Files. Those solutions can also bring some value to offer flexible storage and consolidated files share with more or less performance and SMB or NFS flavours depending what you choose. But as the AWS S3, they are not focus on concurrence and simplify a consolidated photo for users all over the world.
Google Suit + Google Drive. It is another content collaboration platform as Sharepoint Online + One Drive. It´s not exactly the same but both embrace sharing and collaborative work for the users documents all over the region.
Azure file sync scenario
Shapoint Online + One drive and Gsuite + GDrive are productivity cloud products while Azure File sync or Amazon Fsx + DFS are more infrastructure approaches. For those with a very limited budget and needs to reduce operational complexity, to increase productivity and improve UX (user experience), we are going in depth with them in the next post.