

As I showed in the previous post Azure file sync needs an agent to be installed in your Windows File Servers thought Windows Admin Center or directly if you download it and install it in your file server. Once it´s done you can proceed to leverage the power of this feature in your global environment, but please take into account the agent is right now only available with the following operating system for your file servers.

Remember to create an Azure file sync, you need an storage account as we did in the previous post, (better general purpose v2), a file share and install the agent on those file server where you want to share data. Then as we did, you can proceed to configure the cloud endpoint and servers endpoint within your sync group on the Azure Portal.

Add the servers from several braches and obviously your head quarter file server..

Verify your servers are synchronized..



Proceed to create a file in your local head quarter file server..

It is automatically replicated on our example to the branch file server..
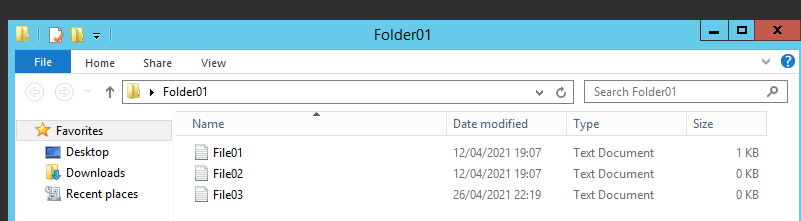
Even if you pay attention to the File share in the Azure Portal you can see all the files from both servers (one in the Head quarter and the other one your branch file server) replicating their data on the File Share in Azure..
Now imagine, you have users all over the world, you need your employees are working on the same page with flexibility and on demand, even you need a backup of that day from time to time and a disaster recovery strategy. Even more, you need to empower your users to be more productive remotely, with their MacOS or Windows Laptops from anywhere.
You can have users working with the same files all around the world and several operating systems (MacOS, Windows 7 , 8.1 or 10 and Linux Ubuntu, Red hat or CentOS) leveraging any protocol that’s available on Windows Server to access your data locally, including SMB, Network File System (NFS), and File Transfer Protocol Service (FTPS). For them it´s transparent where the files are.
But what about performance and scalability?…Well, You can create as much sync groups as your Infrastructure would demand. Just be aware you should design and plan thinking on the amount of data, resiliency and Azure regions where you are extending your business. Anyway it is important to understand the way our data it will be replicated:
- Initial cloud change enumeration: When a new sync group is created, initial cloud change enumeration is the first step that will execute. In this process, the system will enumerate all the items in the Azure File Share. During this process, there will be no sync activity i.e. no items will be downloaded from cloud endpoint to server endpoint and no items will be uploaded from server endpoint to cloud endpoint. Sync activity will resume once initial cloud change enumeration completes. The rate of performance is 20 objects per second
- Initial sync of data from Windows Server to Azure File share: Many Azure File Sync deployments start with an empty Azure file share because all the data is on the Windows Server. In these cases, the initial cloud change enumeration is fast and the majority of time will be spent syncing changes from the Windows Server into the Azure file share(s).
- Set up network limits: While sync uploads data to the Azure file share, there is no downtime on the local file server, and administrators can setup network limits to restrict the amount of bandwidth used for background data upload. Initial sync is typically limited by the initial upload rate of 20 files per second per sync group.
- Namespace download throughput When a new server endpoint is added to an existing sync group, the Azure File Sync agent does not download any of the file content from the cloud endpoint. It first syncs the full namespace and then triggers background recall to download the files, either in their entirety or, if cloud tiering is enabled, to the cloud tiering policy set on the server endpoint.
- Cloud Tiering enabled. If cloud tiering is enabled, you are likely to observe better performance as only some of the file data is downloaded. Azure File Sync only downloads the data of cached files when they are changed on any of the endpoints. For any tiered or newly created files, the agent does not download the file data, and instead only syncs the namespace to all the server endpoints. The agent also supports partial downloads of tiered files as they are accessed by the user.
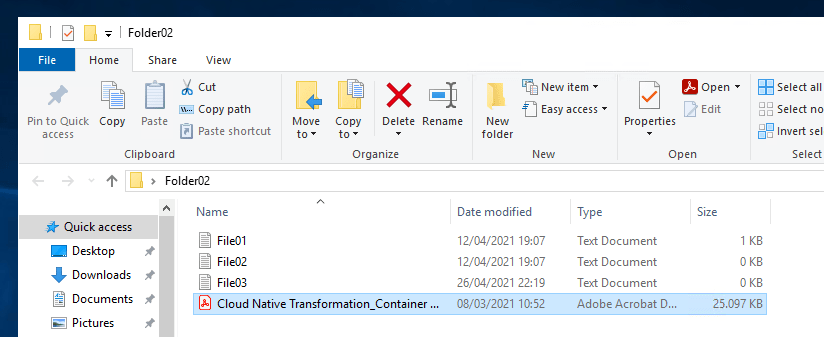
Here I show an example with a 25 MB file. Synchronization was almost immediate as the Sync Groups was already set up. If we upload a file to Folder 02 in our head quarter file server you can see it on the branch in the Folder 01 as well in a matter of second or even less depending on the configuration as we said..

Azure Files supports locally redundant storage (LRS), zone redundant storage (ZRS), geo-redundant storage (GRS), and geo-zone-redundant storage (GZRS). Azure Files premium tier currently only supports LRS and ZRS. That means an incredible potential to replicate data depending on resilience and with solid granularity to several regions in the world.
In the next post we´ll see how to integrate Azure File with AAD or enhance your Windows VDI strategy with FSLogic app containers. See you them..
